UC Davis · 2024
Explainable Writing Style Detection
Built an interactive authorship attribution system that combines fastText with SHAP and LIME, achieving strong multi-author classification performance while making predictions interpretable to end users.
This project studies writing style detection and authorship attribution with an emphasis on interpretability. Instead of only predicting which author a piece of writing most resembles, the system also explains why that prediction was made, helping users see which words and stylistic cues influenced the result.
The project was designed as an interactive end-to-end system: a fastText-based classifier for sentence-level authorship prediction, a similarity scoring module for comparing input text against known authors, and a Tornado web interface for real-time visualization.
What I did
- Built and trained the authorship attribution model.
- Framed the task at the sentence level to improve interpretability.
- Integrated SHAP and LIME to explain model predictions.
- Developed a pipeline for similarity scoring between user text and reference authors.
- Helped evaluate both model quality and system efficiency in an interactive setting.
Key idea
A key design choice was to avoid treating the input as one opaque block of text. Instead, the system splits writing into sentences, classifies them with fastText, and then aggregates the results. This makes the prediction pipeline easier to interpret and also enables token-level explanation through SHAP and LIME.
Beyond classification, the project computes cosine similarity between the input text and reference texts so that users can see not only the predicted author, but also how closely their writing aligns with different styles.
Main findings
We trained and compared two fastText models: a basic version and an auto-tuned version. The auto-tuned model clearly performed better, reaching a P@1 of 94.7%, compared with 75.4% for the basic model. The report argues that this improvement is especially meaningful in the multi-author setting, where the classifier must separate many stylistically similar classes.
We also compared SHAP and LIME as explanation methods. In our experiments, SHAP was substantially more computationally efficient, especially as input length increased, making it the better choice for a real-time interactive system.
Finally, the Tornado server showed good scalability under increasing request load and longer text inputs, suggesting that the system was practical as an interactive web tool rather than just an offline experiment.
Dataset and scope
The full dataset contains 3,036 English-language books by 142 authors, but for the implemented system we used a curated subset of 10 authors to make training and evaluation more manageable. These authors were selected to span a range of literary styles, from Agatha Christie and Jane Austen to Walt Whitman and Winston Churchill.
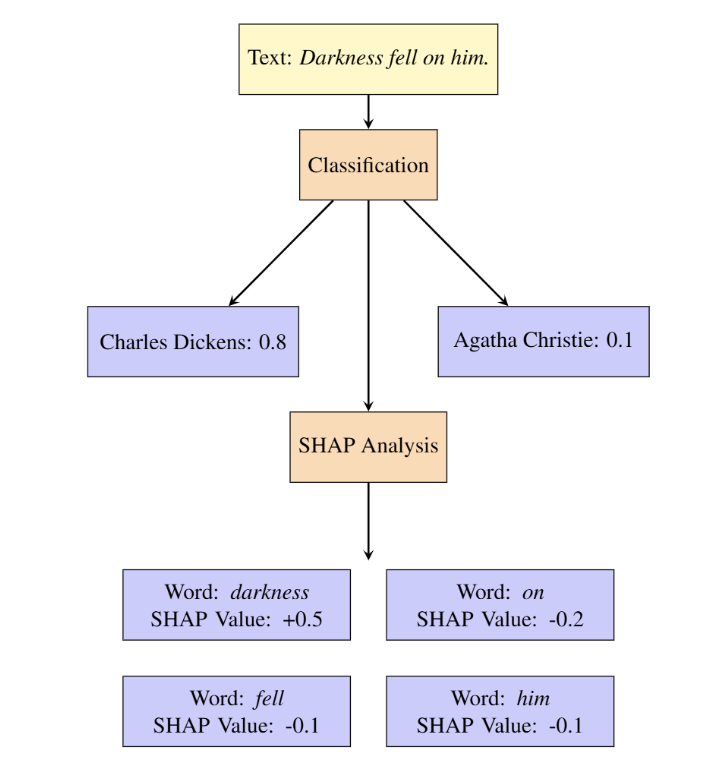
Explainability in action
A central contribution of the project is that the model does not stop at prediction. With SHAP and LIME, the interface can highlight which words or phrases push a sentence toward one author over another. This makes the system more useful for education and exploration, since users can inspect stylistic signals rather than receiving only a label.
Interactive interface
The repository includes a Tornado-based web interface that lets users submit text and receive classification results, similarity scores, and explanations in real time. This made the project feel more like a usable application than a standalone model benchmark.
Course context
This project was completed for ECS 171: Machine Learning at UC Davis in Summer Session 2, 2024, and received full marks.