UC Irvine · 2026
Undergraduate Researcher, HPC Forge @ UC Irvine
Studied fused W4A16 INT4 weight-only GEMM in Triton for LLM inference, with implementations and benchmarks for decode and prefill regimes.
HPC Triton LLM Inference GPU Kernels
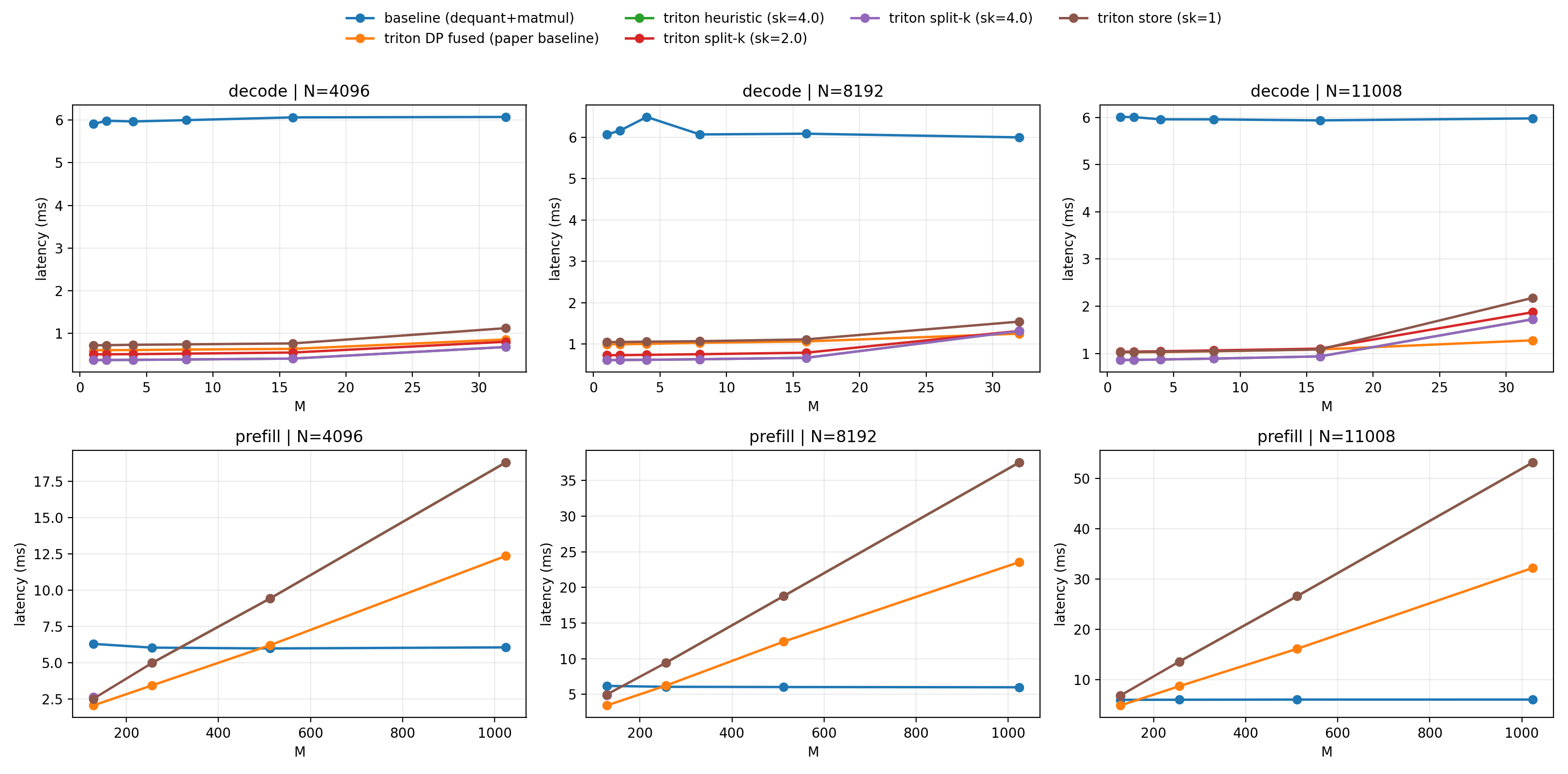
Details coming soon.
Advised by Prof. Aparna Chandramowlishwaran under EECS 199.
This page should eventually include:
- problem setting
- kernel design
- benchmarking setup
- main results
- report link
- repository link